
前言
近年来,各种互联网金融机构和基金公司一直都在教育散户投资者进行基金定时定额投资或定时不定额投资。关于基金定投的收益和风险不在本文的讨论之列,读者可自行在网上搜索。下面仅谈谈我个人关于基金定投(以下简称“定投”)的看法。
无论互金们怎么把定投吹上天都不要相信,最重要的是自己掌握复盘的方法。对历史行情复盘后发现,按照定投的方法,无论在何时买入,到某个时间点总能实现盈利。所谓Any time is the best time——只要市场行情的整体趋势是向上的即可。因此定投是比较适合没时间盯行情,又打算拿出一笔钱来进行长期投资的职场人士。
基金类型又分为很多种,依据定投的天然属性,越是波动剧烈的基金越是适合进行定投。所以,偏股类基金或者以某个指数作为投资标的的基金是最好的选择。同时,为了分散风险,即鸡蛋不放在同一个篮子里,可以同时选择多支指数/偏股基金进行定投。
要做,就要做到最好。为了最大程度的分摊风险,所选的基金行情走向应该呈现不相关甚至是负相关的关系。因为,若是选择了两只相关的基金,同时大涨固然好。若是同时大跌,又选择了定期不定额的“慧定投”模式,可能在几天之内就会把“子弹”(计划用于投资的资金)打光。所以,当选择了两只不相关的基金,在一只赚钱到达止盈线之后可以进行收割,也有更充足的“弹药”应对另一只走低的基金。
指定的两只基金的相关性还算是容易计算。抓取K线后复权的收盘价之后,用EXCEL里面的CORREL函数即可计算出来。几只基金两两之间的收盘价,辛苦一点也是可以扒拉出来的。但是几十只基金之间的呢?以及如何从中选择出相关性比较低的一种组合呢?
目标
我个人从去年就开始了第一笔定投,当时主要是结合股市常识选择了5个指数,哪些基金追踪的这些指数就不说了。上证50,代表大型公司。中证500,代表中型公司。创业板指,代表创业型公司。恒生国企指数,代表港股。纳斯达克指数,代表美股。它们之间很明显的没有互相包含关系,所以即使不用算也知道它们的平均相关性很低。但是现在正值股灾,我想在此基础上再多定投几只指数(基金),以此来调整个人的资产配置比例。适逢我人生哲学的其中一个信条就是:
“重复的事情交给机器去做,解放出劳动力来进行更有意义的创造。”
因而我编写了一个程序,专门用来计算多项数据之间的平均相关性,并从中挑选出相关性最低的组合。是的,它不仅仅可以用来计算指数或股票走势的相关性。任何多项数据都可以,只要每项数据的数据元素个数一致即可。因为本来计算相关性的公式就要求如此。
步骤
第一步,准备好数据源。
我从沪深(中证)、上证、深证、港股、美股中挑选出了21个指数作为备选项。挑选的条件是能够从蚂蚁财富中买到相应的跟踪基金,并且可选的基金个数不少于两个。主题指数不参与计算,有兴趣的读者可以自行实现。然后从行情软件中下载好2017年10月16日到2018年10月16日的每日收盘价。
第二步,进行数据清洗。
按日期(按列)码齐每个指数是最基本的。然后就会发现A股(大陆)指数、港股指数、美股指数都会出现不连续的空隙。这是由于各个证交所放假导致交易日不同而导致的。对于这些数据,我采用了手工进行线性插值的方法处理。这部分数据对整体的影响不大。为了避免后面涉及到对XLS文件的繁琐编程,把该sheet数据单独保存为一个CSV文件。这样即可在编程的时候使用普通的文件流读取方法把数据载入内存中。
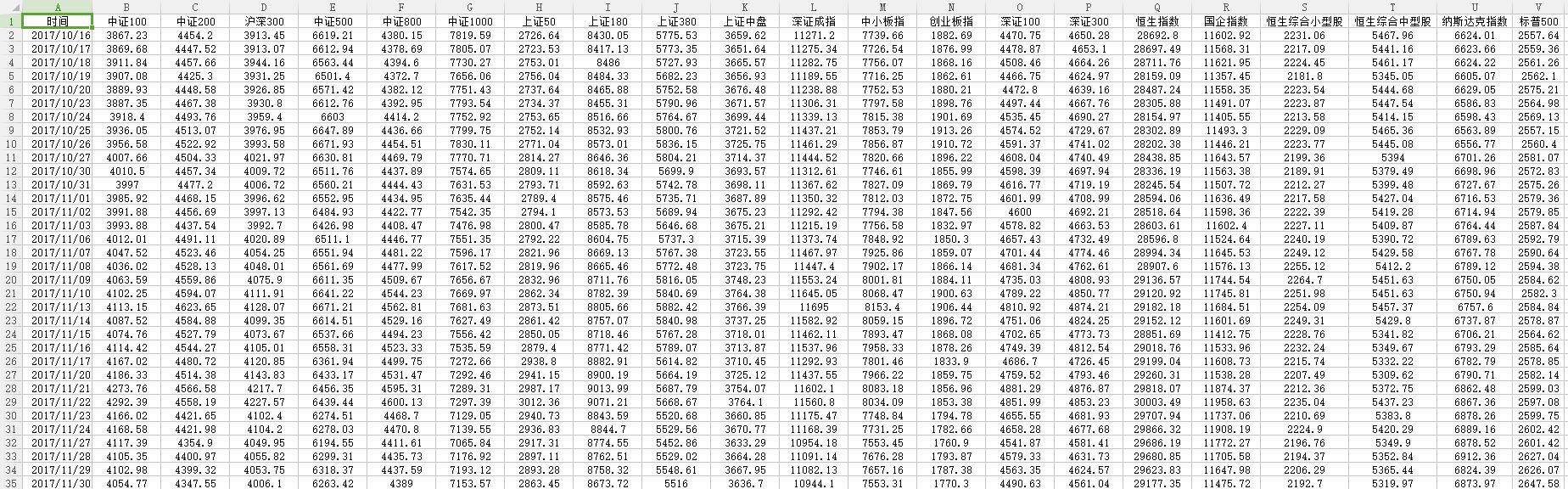
第三步,建立验证数据。
由于是第一次进行该类编程,还需要有一个参考标准来对比验证程序的计算结果。因此我又在EXCEL中利用CORREL公式计算了出所有21个指数两两之间的相关度。
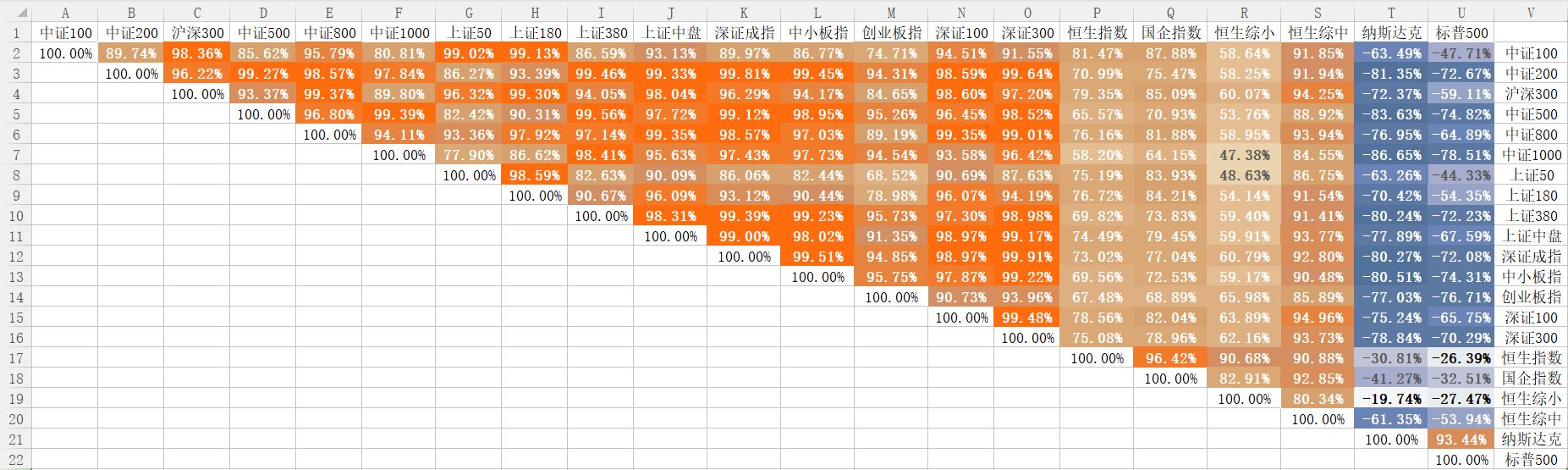
第四步,编程。
4.1读取CSV文件,并格式化地保存进原始集合。由于文件是存储在硬盘上的,而硬盘的读写速度远比内存低。因此计算前先将数据读入到原始集合,然后按一定的格式(类或结构体)来存储每条数据是以后计算的基础。
4.2单独抽出指数据标志(指数名称)保存进名称集合。后面对指数进行组合时,依据的是指数的唯一标志,即指数的名称。而带着几百条收盘价一起进行组合是没有必要且浪费资源的。输出所有读取到的指数(名称)给用户进行检查。
4.3对数据标志进行两两组合。这里建立了一个递归函数,实现对输入N个元素中抽K个进行组合保存进配对集合。每种组合只出现一次,组合中无重复的元素,组合内元素无顺序区别。这样才能符合实际需求。该函数主要使用了高级的Linq查询技巧,但可能并不是时间和空间上的最优解,是一个可接受的解。
4.4求配对集合中每个组合的相关度。建立一个与CORREL函数计算方法一样的代数计算函数。遍历组合,用每个组合中元素1和2的名称在原始集合中找到对应的收盘价数组,并一同放入计算函数中计算。这里就得到了与第三步中两两指数相关度一样的结果,并可以对结果进行检验,以验证组合函数和计算函数的正确性。
4.5对数据标志进行K个元素的组合。按照用户的需求,从N个元素中每次抽取进行K个元素的组合,并存放进一个新的结果集合中。
4.6遍历结果集合,组合出在每个组合(A组合)中元素的两两组合,然后从配对集合中查询出一样的组合并取出相关度放入A组合中。当查询完成时,A组合中就同时包含了K个元素和K个元素两两之间的所有相关度。这里的逻辑嵌套层次较多,文字描述不清楚可直接看代码。
4.7对结果集合中的A组合进行排序,排序依据为每个A组合的平均相关度。按用户需求数量输出A组合的内容。
4.8对用户输入的数据标志(指数名称)字符串进行分割。如输入了M个指数名称则利用循环进行M次查询。每次查询寻找出所有包含当前数据标志的A组合形成一个新的筛选集合,抛弃其他组合。然后下一个数据标志从刚刚得到的筛选集合中查询。经过M次比较后即可得出满足用户输入最终筛选集合。然后输出给用户检验。
用法
对我而然,首先将准备好的CSV文件和编译好的IndexCorrelation.exe放在同一目录下。然后打开EXE,输入CSV的文件名。
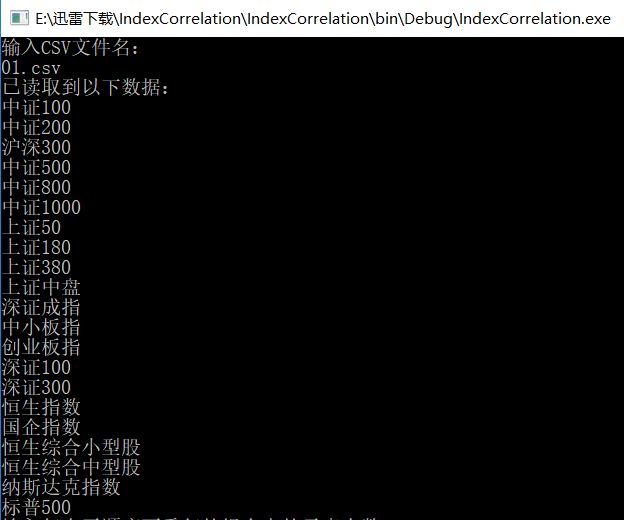
如我想在原来已有的5个指数基础上再增加1个指数,则按6个指数一组进行组合。
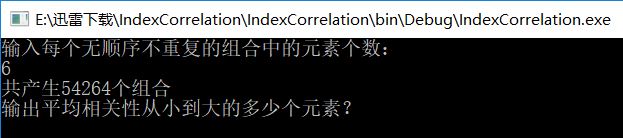
这时程序会给出一共可能产生的组合个数。之后我想阅览相关性最小的10个组合。
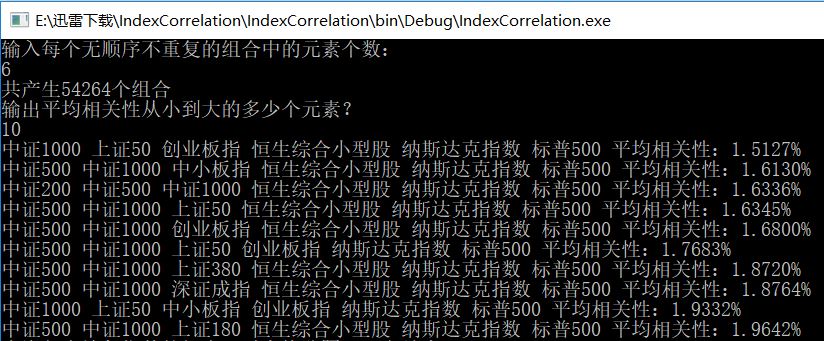
程序会按平均相关性从小到大罗列。最后,我根据我现有的投资条件进行查询。
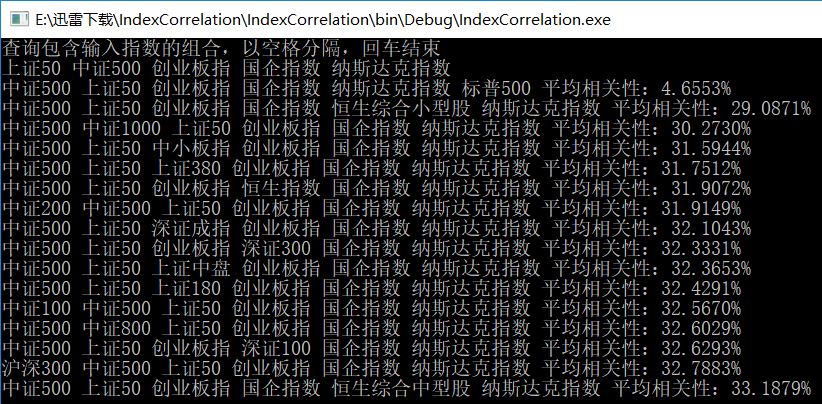
根据我现在的投资条件,选择添加标普500进入我的指数定投序列会是平均相关性最低的选择,但不一定是最好的选择。这是显然的,因为标普500和A股指数、港股指数都是负相关的,只和纳斯达克是正相关的,会严重拉低整个平均相关性。
后语
老读者可能会发现,在准备原始集合的部分,完全可以参照《基于C#的股票数据获取并进行基础分析的程序》一文中的程序,从网上直接下载指数数据。是的,如果只是用于分析证券市场数据的相关性的确可以这样做。我目前使用文件导入的做法是为了方便后面可以对其他类型的数据进行分析。有心的读者可以自行拼接这两个程序。
鉴于本文中的程序大量地使用了集合、泛型、Linq查询等技术。即使不用于进行相关性分析的读者也可以参考其中的编程技巧。再次声明,程序中的所有解法不一定是时间度量和空间度量上的最优解,只是我可以接受的解。
集合(数组)在使用过程中,一定要注意越界访问的问题。我作为编程人员和使用者,会自然而然地只输入合法的条件进入程序。感兴趣的读者可以自行检查所有可能会发生越界访问的地方。
发表回复