
目标
本文的目标是在学习了TensorFlow的官方Graph Execution示例后,通过举一反三运用其他例子来进一步理解官方示例。因此,本文中的所有结果仅作学术研究用途。
前提
IDE准备
Visual Studio 2017
打开Visual Studio Installer修改当前使用的VS,确保工作负载中Web和云分类下的Python开发被选中。然后切换到单个组件,确保开发活动中的Python语言支持和编译器、生成工具和运行时中的Python 3 64-bit被勾选。
点击右下角的修改,等待组件被下载和安装。
项目准备
新建一个Python应用程序项目。在解决方案资源管理器中找到Python环境,并右键添加虚拟环境。虚拟环境的基础解析器为Python 3中的某个版本。
右键点击新建的虚拟环境,选择安装Python包。
分别安装pip、pandas和tensorflow。这些包在安装的同时,会把所有需要的包进行链式安装。以防万一,以下列出需要用到的所有包及版本。
[code lang=”text” collapse=”true” title=”requirements.txt”]
absl-py==0.2.2
astor==0.6.2
bleach==1.5.0
certifi==2018.4.16
chardet==3.0.4
cycler==0.10.0
gast==0.2.0
get==1.0.3
grpcio==1.13.0
html5lib==0.9999999
idna==2.7
kiwisolver==1.0.1
Markdown==2.6.11
matplotlib==2.2.2
numpy==1.14.5
pandas==0.23.1
pip==10.0.1
post==1.0.2
protobuf==3.6.0
public==1.0.3
pyparsing==2.2.0
python-dateutil==2.7.3
pytz==2018.5
query-string==1.0.2
request==1.0.2
requests==2.19.1
setuptools==39.2.0
six==1.11.0
tensorboard==1.8.0
tensorflow==1.8.0
termcolor==1.1.0
urllib3==1.23
Werkzeug==0.14.1
wheel==0.31.1
[/code]
数据准备
既然要进行机器学习,就需要准备好训练数据集和测试数据集。训练数据集用于构建出一个能根据特征值推断出标签值的模型,而测试数据集用于评估这个模型的准确度,它们都来自一个数据超集。为了有效地对模型进行评判,测试数据集与训练数据集不能有交集。
我构建的数据超集每一行代表一场比赛,因为我希望以一场比赛为单位预测它的赛果,并有如下的列,并描述为什么我要纳入这些列:
- 序号:描述这是第几场比赛。随着赛程时间的进行,球员逐渐适应气候环境的情况以及产生的疲倦都可能会影响赛果。
- 主队:以数字的方式表示这场比赛的主队。我按出场顺序为每支球队定义了一个编号,实际上编号的大小无所谓,只要在整个数据集中用同一个编号表示同一支球队即可。编号对应的球队在后面会给出。
- 客队:以数字的方式表示这场比赛的客队。
- 主队胜的平均初始赔率:赔率代表着某家公司对该场比赛该队表现的看法,它本身即是各种可能影响比赛因素的一个综合提炼。而取多家公司的平均赔率更具客观性。
- 平局的平均初始赔率
- 主队负的平局初始赔率
- 主队胜的平局即时赔率:通过与同一行中的初始赔率作比较,获得赔率变化。这个变化可能是因为某些临赛前影响比赛的因素变化所导致的,也可能是公司一开始在掩盖自己的真实意图。即时赔率在数据超集中为截止投注前的最后一次公布的赔率,而在预测条件中为当前得知的最后一次公布的赔率。
- 平局的平均即时赔率
- 主队负的平均即时赔率
- 主队近10场比赛的胜场数:近期比赛会在一定程度上反映出该队伍的状态。
- 主队近10场比赛的平场数
- 主队近10场比赛的负场数
- 客队近10场比赛的胜场数
- 客队近10场比赛的平场数
- 客队近10场比赛的负场数
- 主队积分:这场比赛开始前,按小组赛规则的积分。因为数据集中也纳入了淘汰赛的数据,所以也按胜方积3分,平局各积1分,负方不积分的方式统计。积分在一定程度上反映了之前的比赛结果对该队伍造成的影响。
- 客队积分
- 赛果:以数字方式表述这场比赛的结果。主胜为2,平局为1,主负为0.
前17列为特征列,每列中的每个值即为特征值。最后一列为标签列,每列中的每个值即为标签值。机器学习的目的就是找出已知的特征值与特征值组合和已知标签值之间的关联,然后根据已知的特征值去预测未知的标签。
这些数据的来源通常可以在投注网站找得到。
这时前提准备已经完成,可以往项目中添加.py文件及代码。
代码展示
先上代码,然后对代码进行讲解。
[code lang="python" collapse="true" title="WorldCupPredict.py"]
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import argparse
import tensorflow as tf
import game_data
parser = argparse.ArgumentParser()
parser.add_argument('–batch_size', default=4, type=int, help='捆绑大小')
parser.add_argument('–train_steps', default=2000, type=int,
help='训练步数')
def main(argv):
args = parser.parse_args(argv[1:])
# 拉取数据
(train_x, train_y), (test_x, test_y) = game_data.load_data()
# 描述输入特征列
my_feature_columns = []
for key in train_x.keys():
my_feature_columns.append(tf.feature_column.numeric_column(key=key))
# 构建DNN分类器
classifier = tf.estimator.DNNClassifier(
feature_columns=my_feature_columns,
# 3个隐藏层
hidden_units=[20, 15, 5],
# 设置3个类别
n_classes=3)
# 训练模型
classifier.train(
input_fn=lambda:game_data.train_input_fn(train_x, train_y,
args.batch_size),
steps=args.train_steps)
# 评估模型
eval_result = classifier.evaluate(
input_fn=lambda:game_data.eval_input_fn(test_x, test_y,
args.batch_size))
print('\n测试集准确度: {accuracy:0.3f}\n'.format(**eval_result))
# 建立需要使用模型做出预测的数据
predict_x = {
'Game': [57],
'Home': [4],
'Away': [9],
'WinInitialOdds': [4.3],
'DrawInitialOdds': [3.17],
'LossInitialOdds': [2.00],
'WinCurrentOdds': [4.44],
'DrawCurrentOdds': [3.11],
'LossCurrentOdds': [2.03],
'HomeWinCount': [8],
'HomeDrawCount': [1],
'HomeLossCount': [1],
'AwayWinCount': [6],
'AwayDrawCount': [3],
'AwayLossCount': [1],
'HomePoint': [12],
'AwayPoint': [10]
}
predictions = classifier.predict(
input_fn=lambda:game_data.eval_input_fn(predict_x,
labels=None,
batch_size=args.batch_size))
template = ('\预测结果是"{}" ({:.1f}%)"')
for pred_dict in predictions:
class_id = pred_dict['class_ids'][0]
probability = pred_dict['probabilities'][class_id]
print(template.format(game_data.RESULT[class_id],
100 * probability))
if __name__ == '__main__':
tf.logging.set_verbosity(tf.logging.INFO)
tf.app.run(main)
[/code]
[code lang="python" collapse="true" title="game_data.py"]
import pandas as pd
import tensorflow as tf
TRAIN_URL = "http://120.77.11.178/wp-content/uploads/2018/07/game_training.csv"
TEST_URL = "http://120.77.11.178/wp-content/uploads/2018/07/game_test.csv"
CSV_COLUMN_NAMES = ['Game','Home','Away',
'WinInitialOdds','DrawInitialOdds','LossInitialOdds',
'WinCurrentOdds','DrawCurrentOdds','LossCurrentOdds',
'HomeWinCount','HomeDrawCount','HomeLossCount',
'AwayWinCount','AwayDrawCount','AwayLossCount',
'HomePoint','AwayPoint','Result']
RESULT = ['Loss','Draw','Win']
def maybe_download():
train_path = tf.keras.utils.get_file(TRAIN_URL.split('/')[-1], TRAIN_URL)
test_path = tf.keras.utils.get_file(TEST_URL.split('/')[-1], TEST_URL)
return train_path, test_path
def load_data(y_name='Result'):
"""以(train_x, train_y), (test_x, test_y)的形式返回比赛数据集"""
train_path, test_path = maybe_download()
train = pd.read_csv(train_path, names=CSV_COLUMN_NAMES, header=0)
train_x, train_y = train, train.pop(y_name)
test = pd.read_csv(test_path, names=CSV_COLUMN_NAMES, header=0)
test_x, test_y = test, test.pop(y_name)
return (train_x, train_y), (test_x, test_y)
def train_input_fn(features, labels, batch_size):
"""训练输入函数"""
# 将输入转换为数据集
dataset = tf.data.Dataset.from_tensor_slices((dict(features), labels))
# 打乱、重复以及捆绑样本
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
# 返回数据集
return dataset
def eval_input_fn(features, labels, batch_size):
"""验证和预测输入函数"""
features=dict(features)
if labels is None:
# 没有标签,只有特征
inputs = features
else:
inputs = (features, labels)
# 将输入转换为数据集
dataset = tf.data.Dataset.from_tensor_slices(inputs)
# 捆绑样本
assert batch_size is not None, "batch_size must not be None"
dataset = dataset.batch(batch_size)
# 返回数据集
return dataset
CSV_TYPES = [[0.0], [0.0], [0.0],
[0.0], [0.0], [0,0],
[0.0], [0.0], [0.0],
[0.0], [0.0], [0.0],
[0.0], [0.0], [0.0],
[0.0], [0.0], [0]]
def _parse_line(line):
# 解码行
fields = tf.decode_csv(line, record_defaults=CSV_TYPES)
# 将结果打包为字典
features = dict(zip(CSV_COLUMN_NAMES, fields))
# 将标签从特征中分离
label = features.pop('Species')
return features, label
def csv_input_fn(csv_path, batch_size):
# 创建一个包含多行文本的数据集
dataset = tf.data.TextLineDataset(csv_path).skip(1)
# 转换每一行
dataset = dataset.map(_parse_line)
# 打乱、重复和捆绑样本
dataset = dataset.shuffle(1000).repeat().batch(batch_size)
# 返回数据集
return dataset
[/code]
首先说WorldCupPredict.py的代码。引用了一些固定的模块,然后确定了步数(step)和捆绑(batch)两个参数。步长并不是越大越好,模型的准确度会从第一步开始逐渐波动上升,到达某个最大值值后可能会下降一点然后再上升一点。当训练数据多的时候,捆绑值可以设大一点。具体意义参考TensorFlow官网的术语表。
然后会调用game_data模块获得训练数据和测试数据。再对特征值进行标记。之后构建了一个分类器,因为实质上这是个按特征把比赛归类为主胜、平局和主负三种不同赛果的问题。
分类器中设置了三个隐藏层,每一个特征值都会流进第一层的每个神经元里,第一层神经元的计算结果又会流进第二层,如此类推。直至输出到三个不同的赛果类别中。最佳的隐藏层数的设置和每层神经元数的设置需要通过重复实验和一定的经验决定。往往多的层和多的神经元需要更多的训练数据去达到有效的训练。
训练完成后会使用测试数据对模型进行评估,并给出准确度。之后可以手动构造一个或多个比赛数据给模型预测。这里使用的是第57场乌拉圭对战法国的数据,这里并没有给出赛果作为标签值。
模型会根据特征值预测出归属于不同标签的可能性,这里文本输出了最大可能性的标签及其可能性。
接下来说一下game_data.py的代码。首先定义了两个数据源,采用的是本网站整理好的训练集和测试集。数据源的形式是csv文件,是一种以换行表示数据行,逗号表示一行中的数据列的表格型数据。
首先需要从网络把数据源下载回到本地,然后将csv数据源整理成可以被计算的张量(tensor)。解析csv文件需要用到一个数据模板向程序说明每列是一个什么数据类型的数据。这里把前面17列的特征值作为浮点数,最后一列作为整数。因为张量转换过程中所有数据的类型要相同。这个文件的代码主要是做了数据整理的工作。
运行结果
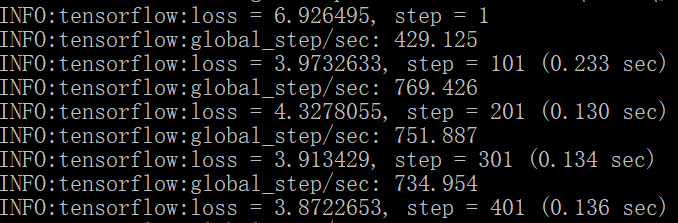
过程中会给出在训练模型时的信息,包括了步数、进行到当前步数的损失和每秒进行了多少步。
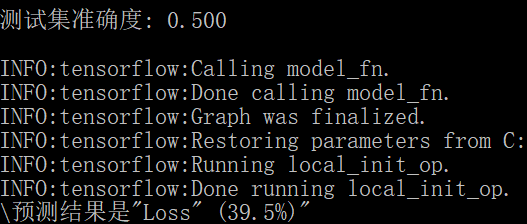
模型训练完成后,会放入测试集,用于评估模型的准确度。最后会给出一个无标签的特征值的标签预测结果。如上图所示,即评估准确度达到50%,而有39.5%的概率本场(乌拉圭VS法国)的比赛中,主队(乌拉圭)会输。
读者可以尝试进行以下几种工作:
- 调整步长和捆绑对训练和评估的影响。
- 调整隐藏层数和神经元个数对训练和评估的影响。
- 加入新的特征列和删除已有特征列对训练和评估的影响。
- 把该项目作为模板处理其他分类问题。
- 壕砸2块钱法国赢。
发表回复